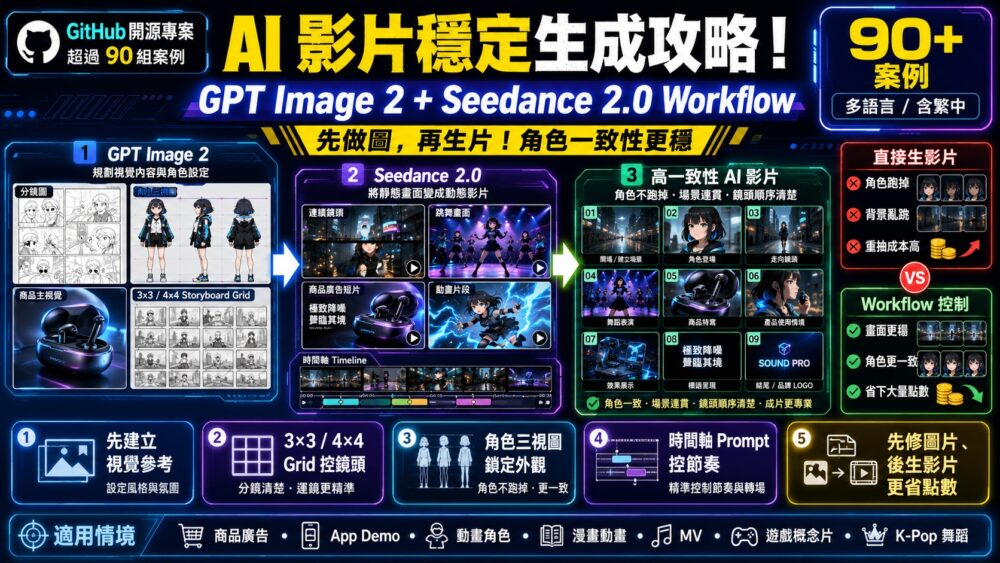
隨著 Seedance 2.0 的推出,AI 影片的表現大幅躍進,只要輸入提示詞,就能生成相當有感的短片。然而,要穩定產出角色與場景高度一致的 AI 影片,仍然是一大挑戰:角色前一秒還是同一張臉,下一秒就換了個人;場景一轉,背景就全亂了。尤其影片的生成成本遠高於圖片,若反覆重抽,花費相當驚人。
如果你也遇到類似困擾,用GitHub這個「GPT Image 2 + Seedance 2.0 Workflow」絕對值得收藏。該專案由 EvoLinkAI 整理發布,收錄超過 90 組實戰案例,每組皆附上完整提示詞與原創作者連結,示範如何先用 GPT Image 2 規劃畫面、角色與分鏡,再交由 Seedance 2.0 轉換為連貫穩定的影片。
為什麼這個專案這麼實用?
「GPT Image 2 + Seedance 2.0 Workflow」是一套專注於 AI 影片生成流程、提示詞範本與實際案例的參考資料庫。核心做法是:先由 GPT Image 2 產出圖片、分鏡、角色三視圖或商品視覺,再由 Seedance 2.0 將這些靜態畫面轉為動態影片。換句話說,GPT Image 2 決定「畫面長什麼樣」,Seedance 2.0 負責「畫面怎麼動」,兩者搭配,讓 AI 影片不再靠運氣,而是透過可控的分鏡、格狀參考圖、時間軸提示詞等方法,顯著提升畫面連貫性與角色一致性。
專案中的案例大多來自 X 平台創作者,涵蓋商品廣告、App 展示、動畫角色、漫畫動畫、音樂影片、遊戲概念片、K-Pop 舞蹈、奢華品牌短片等多元類型。除了可以直接複製與修改提示詞,更能學習創作者如何將一部影片拆解為可控的畫面流程,例如:
專案特色亮點
-
整理 GPT Image 2 與 Seedance 2.0 的實際搭配流程
-
收錄大量真實創作者案例與提示詞範本
-
支援分鏡圖、3×3 宮格、4×4 動作格等影片控制方式
-
適用於商品廣告、App 展示、動畫、MV、遊戲概念片等多種場景
-
強調角色一致性、畫面連貫性與鏡頭順序控制
-
提供時間軸提示詞、角色三視圖、漫畫頁動畫等進階技巧
如何使用?
專案提供多語言版本(含繁體中文),進入後可直接點選 zh-TW.md 檔案。
內容非常豐富,包含基本介紹、分鏡技巧、各類案例說明、技巧分類、一致性指南與提示詞範本。
頁面下方有完整目錄
也可點擊右上角圖示開啟目錄表,快速切換主題。主要分類包括:商業與產品、動畫與角色、音樂影片與短片、遊戲概念、製作工具、社群精選。
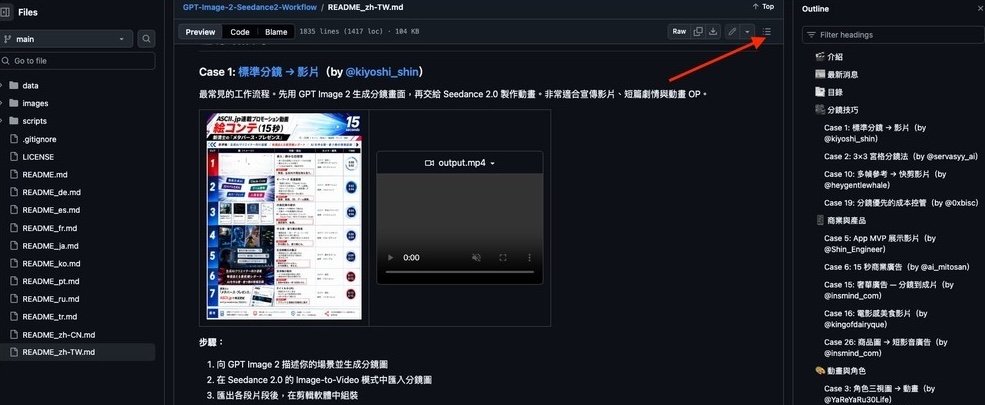
建議先閱讀最前面的分鏡技巧,了解 GPT Image 2 與 Seedance 2.0 的搭配邏輯、關鍵技巧、推薦提示詞,甚至成本控管方式。
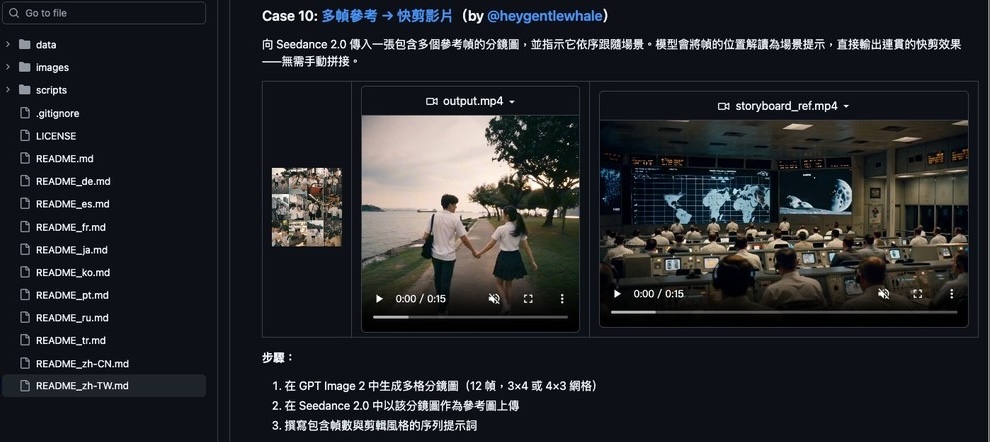
掌握這些基礎後,再看其他案例會更能理解每位創作者的實作思維。每個案例都附上實際生成的影片,讓你可以直接對照效果。
想生成跳舞影片?請看 Case 13。

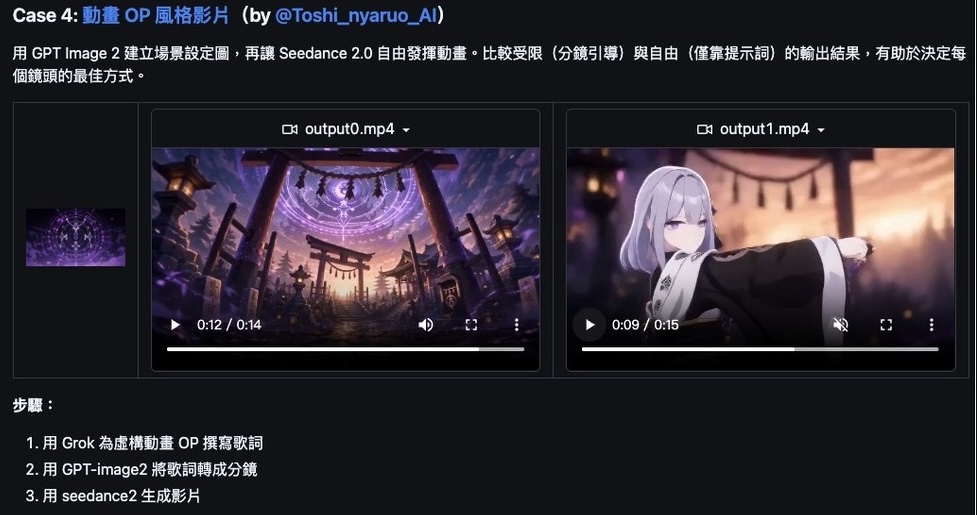
想學動畫 OP 風格影片?Case 4 值得參考。
由於專案內含大量影片,線上瀏覽可能稍微卡頓,建議可將專案 Clone 到本地端使用。
你一定要知道的關鍵技巧
-
不要直接生成影片,先建立視覺參考
AI 影片要穩定,關鍵是不要讓模型自己腦補。先用 GPT Image 2 準備好分鏡、角色設定圖、商品圖或場景圖,再進入影片階段。
-
分鏡越清楚,影片越穩定
使用 6 格、8 格、12 格分鏡,每格只負責一個明確動作,避免資訊過多。指令越單純,輸出越接近預期。
-
Grid 圖能大幅降低鏡頭混亂
3×3、3×4、4×4 的格狀圖是專案中最常見的方法。它讓 Seedance 在同一張圖中看到完整順序,比逐張輸入更能避免不連貫問題。若要做時間順序明確的快剪,請在提示詞中加入 follow the storyboard sequence of the [N] reference frames 這類指令,告訴模型「這是時間軸」。
-
角色動畫一定要先做角色設定圖
不要每次都用文字描述角色。三視圖永遠比純文字提示詞穩定。
-
用時間軸 Prompt 控制影片節奏
參考 Case 16 的做法,將 15 秒拆解為「0–2 秒俯拍特寫、2–4 秒側面慢動作、4–6 秒微距…」,遠比單純寫「做一支漂亮影片」精準許多,特別適合產品展示、食物影片、開箱或操作流程。
-
商品影片要鎖死產品外觀
專案中的 Consistency Guide 提到一個小技巧:在 Seedance 的提示詞中加入 keep the product appearance completely unchanged, camera movement only, no rotation(保持產品外觀完全不變,只移動鏡頭,不要旋轉),可避免商品因動態插值而被改寫細節。此外,每段影片時長盡量壓在 3 秒內,時間越短,累積的失真越少。
-
先修圖片、後生影片,省下大量點數
影片重做的成本是圖片的 10 到 50 倍。在圖片階段就把錯誤修正完畢,影片階段只做最終渲染,遠比反覆重抽影片划算得多。



